|
|
|
|
|
|
|
NIEUWSSELECTIE
|
AUTOMATISCHE SPRAAKHERKENNING KAN VEEL, MAAR NIET ALLES
Luister nou toch eens
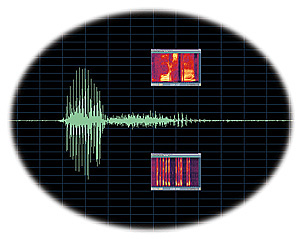
Drukgolf van het woord ‘Assen', met als inzet spectogrammen van de woorden woorden ‘voorstraat' (boven) en ‘cijfer'.
Hendrik Spiering 'Nee, nee, zelfs u zult waarschijnlijk stukken gaan dicteren aan de computer, in plaats van te typen." Thomas Eisele is hoofd van de afdeling Spraakherkenning van Philips Forschungslaboratorien in Aken en hij wil van geen scepsis weten. "Het aantal fouten in het dictaat daalt met 25 procent per jaar. Philips Freespeech 2000 is al weer een stuk beter dan Freespeech 1998", zegt Eisele, die onlangs even in Nederland was op uitnodiging van de TU Delft. Desgevraagd wil hij graag aan de sceptische journalist, die ooit zelf Freespeech 98 probeerde, tonen hoe gemakkelijk het is om een brief aan je computer te dicteren zonder het toetsenbord aan te raken. In een verlaten collegezaal slaat Eisele zijn laptop open. Hij brengt de Philips speechmike naar zijn mond en begint een briefje te dicteren aan ene Dear mr. Müller, die hartelijk bedankt wordt voor zijn voorstel. De omzetting van klank naar letters gaat relatief traag. Samen kijken we toe hoe de woorden op het scherm verschijnen, nadat Eisele al lang klaar is met dicteren. "Dit is maar een 233Hz machine hoor", zegt de research-chef verontschuldigend. "En een belangrijk deel van het geheugen is toegewezen aan een presentatie." Het kattebelletje staat er uitstekend op. Alleen wordt de zin 'I think this is a good one' door Freespeech omgezet in 'I tend to the 5th amendment'. In de correctiemodus suggereert het programma niets wat lijkt op de woorden die bedoeld waren. Vreemd, vindt ook Eisele. Zijn gastheer, de Delftse hoogleraar 'Ergonomie van de telematica' en tevens KPN-researcher Jans Aasman, staat mee te kijken en adviseert: "Herhaal het hele dictaat eens". En inderdaad, dan is het wel goed. Eisele's commando 'Bold september' ('maak het woordje september vet') leidt overigens weer niet tot het gewenste resultaat. Eisele schakelt het programma over van Engels naar Duits, zijn moedertaal. Dat gaat beter. "Ik heb tenslotte een vreselijk accent in het Engels." Slechts twee van de dertig woorden in het korte briefje aan Lieber Herr Müller zijn fout: omgeveer zeven procent rekent Eisele snel uit. "Niet gek. En ik heb dit programma maar een kwartier getraind op mijn stem en mijn woordenschat, het absolute minimum. Hoe meer training, hoe minder fouten."
Toekomstdevies Het lijkt een geschenk uit de hemel in een wereld geteisterd door RSI en managers met toetsenbordangst. Het afgelopen jaar is 'automatische spraakherkenning' definitief het grote toekomstdevies geworden van de computerwereld. Maar de praktijk van alledag is vaak weerbarstig. Het begin van een brief dicteren gaat nog wel, vertelt bijvoorbeeld Jan Houtman, werkzaam op het bureau van de Universiteit van Amsterdam. Afgelopen april zag hij in spraakherkenning door de computer de oplossing voor zijn ernstige RSI-problemen. "Naar aanleiding van uw schrijven deel ik u het volgende mee, dat begreep de herkenner nog wel", zegt Houtman nu. "Maar daarna begonnen de fouten. Ik moest soms wel de helft verbeteren." Twee maanden hield Houtman het vol. Vele uren besteedde hij aan het trainen van zijn Philips Freespeech 98-pakket. Tevergeefs. "Als ik verkouden was, werkte het al niet meer. Het is nog niet goed genoeg." Hoopvol: "Of is de nieuwste versie al weer beter?" Gebruikt Eisele eigenlijk zelf Freespeech? "Niet zo vaak, maar ik hoef ook niet zoveel te typen. En ik typ vrij snel. Als je snel typt, zul je niet snel overstappen op spraakgestuurd schrijven. De hoeveelheid fouten varieert overigens sterk per spreker. Verder is de hoeveelheid training cruciaal. Hoe meer je traint, hoe beter het gaat. En uit onderzoek van onze marketingafdeling blijkt dat een groot deel van de kopers van Freespeech 98 erg tevreden was." Praten tegen je pc is maar een van de drie toepassingen van de moderne spraaktechnologie. De andere zijn telefonische informatiediensten (zie kader) en voicecontrol van apparatuur. Eisele laat zijn mobiele telefoontje zien: een genie. Tien namen onthoudt hij, en als je hem er een opgeeft gaat hij meteen bellen. "De nieuwste kan er zelfs 15 onthouden", aldus Eisele. "Voor de pc zal spraakherkenning lang niet zo'n grote rol gaan spelen als bij dit soort kleine devices in huis of in je zak, met amper of geen toetsenbord. Daar is spraakherkenning ideaal." Aasman is het er helemaal mee eens: "Ik geloof niet dat al pratend formuleren van teksten ooit een hoge vlucht kan nemen. Schrijven is een geheel eigen manier van denken, waarbij praten eerder verwarrend werkt." De hoogleraar telematica, die opgeleid is als cognitief psycholoog, heeft er zelfs een verklaring voor. "Praten is normaal altijd een dialoog, waarbij je helemaal niet hoeft te letten op de precieze formuleringen en de juiste grammatica. Bij schrijven is dat heel anders. En als je niet hoeft te praten, belast je je korte termijngeheugen veel minder." De aanvankelijke opwinding over het feit dat de computer überhaupt iets verstaat, sterft bij menig pc-gebruiker snel weg in praktische onvolkomenheden. De programma's kunnen veel, maar het is nog niet genoeg voor dagelijks gebruik. "Zelfs bij ons in het KPN-lab", zegt Aasman, "hielden RSI-slachtoffers na een tijdje weer op met de spraakpakketten die we voor hen hadden aangeschaft." De taak waartoe programma's als Philips Freespeech, Voice Xpress (van het Belgische Lernout & Hauspie) en Dragon op de Nederlandse markt zijn, is zo ongeveer de moeilijkst denkbare: het omzetten van vrij gesproken woord in begrijpelijke tekst. De meer simpele toepassingen van spraakherkenning werken aanzienlijk beter. "Er zijn principiële grenzen aan de huidige techniek", legt Aasman uit. "De belangrijkste is dat het verstaan van menselijke spraak een zeer actief proces is. Wij mensen gebruiken ontzettend veel achtergrondkennis om te begrijpen wat iemand zegt. Niemand spreekt in correcte zinnen, woorden worden afgebroken, er wordt vaag aan iets gerefereerd met dinges of jeweetwel, klanken worden slordig uitgesproken. Voor ons mensen is dat vrijwel nooit een probleem. Maar een machine ontbeert de veelzijdige achtergrondkennis waarmee wij de spraak 'invullen'. Hij kan alleen kleine stukjes klank vergelijken met klanken in zijn lexicon, zonder dat de betekenis hem op het spoor van de juiste interpretatie zet. Alleen in kleine domeinen is de voor goede herkenning benodigde informatie te overzien." Niettemin, KPN-researcher Aasman wil graag opgeschreven zien dat hij 'absoluut niet negatief' is over de spraaktechnologie. "Het is alleen wel nodig om de verwachtingen te managen. Natuurlijk is de techniek nu nog onvolmaakt, maar ik ben ervan overtuigd dat het goed komt. Er wordt heel veel in geïnvesteerd, binnen twintig jaar zullen we op een natuurlijke manier tegen computers kunnen praten. Wat maakt het uit dat nu negeneneenhalf van de tien programma's mislukken?" In het Engelstalige computerblad Computer Shopper van deze maand (Vol. 19 nr. 11) worden de allernieuwste versies uitgebreid besproken. Aan de gebruikte hardware kan het niet hebben gelegen: de spraakprogramma's werden getest op een Pentium II 450 Hz-computer met maar liefst 384 Mb aan geheugen, een Yamaha DS XG geluidskaart en een Plantronics SR1 koptelefoon/microfoonset. "We zijn onder de indruk", schrijven de testers over de Engelstalige versies van Freespeech 2000, Voice Xpress Professional 4.0, Dragon Naturally Speaking 4.0 en IBM's Viavoice Pro Millenium edition, "maar voorlopig gooien we ons toetsenbord nog niet het raam uit." Geen van de programma's behaalde in de dicteertest een accuraatheid van meer dan 95 procent. Dat is opmerkelijk genoeg, volgens Computer Shopper, maar de stemgestuurde correcties van die vijf procent fouten zijn veel omslachtiger dan verbeteringen via het toetsenbord. Louis Boves, hoogleraar Taal- en Spraaktechnologie te Nijmegen en coördinator van al weer vijf jaar oude NWO-programma 'Spraakherkenning' verbaast zich over de haast waarmee de spraakprogramma's op de commerciële markt worden gebracht. "Ik heb wel eens het idee dat Microsoft, Philips en al die andere grote bedrijven die nu zoveel investeren in de spraaktechnologie, hun spraakprogramma's vooral op de markt brengen om het publiek te laten wennen aan het idee dat ze kunnen praten tegen hun computer, als een soort lange-termijn-opvoedingsprogramma", zegt hij op zijn kamer, bovenin een toren van de Katholieke Universiteit. "Als je die marketingmensen echt onder druk zet, zoals ik laatst eens heb gedaan met iemand van IBM, geven ze toe: 'als je hard werkt aan het trainen van je dicteerprogramma, kun je na een maand ongeveer net zo snel dicteren als iemand tikt met twee vingers. Sneller wordt het niet'." In de herkenning van 'vrije tekst' is een score van 93 95 procent tegenwoordig vrij normaal, aldus Boves, "maar die laatste vijf procent zijn het allermoeilijkst. Brute kracht werkt dan niet meer." Die grens geldt niet voor beperktere toepassingen. In situaties waarin de gebruiker "in feite kan volstaan met het uit menu's aanklikken van items" wordt de score een stuk hoger. Toepassingen waarmee artsen, advocaten en schade-experts spraakgestuurd hun rapporten kunnen opstellen, werken wel goed, aldus Boves. "Dat zijn in feite invuloefeningen. Die mensen werken met vaste protocollen. Ook in Amerikaanse sorteercentra voor pakketten gaat het prima. Moeilijk leesbare postcodes worden daar door medewerkers uitgesproken, waarna de machine er een streepjescode van maakt." De 'brute kracht' waarmee de spraakprogramma's vooralsnog niet boven de 95 procent accuratesse lijken uit te komen, wordt voor een belangrijk deel gegenereerd door het statistische modellen waarop vrijwel alle spraakherkenners zijn gebaseerd: de Hidden Markov Models. Deze berekeningstechniek is genoemd naar de wiskundige Andrey Andreyevich Markov (1856 - 1922), die haar indertijd ontwikkelde om Russische gedichten statistisch te modelleren. Boves: "Als de eerste letter een V is, wat is dan de kans dat de volgende letter een E is? Dat soort berekeningen. Het is een wiskundige techniek om lange rijen van discrete dingen te beschrijven. In de spraakherkenners wordt de techniek op een aantal niveaus tegelijkertijd gebruikt. Zinnen worden beschouwd als rijen van woorden. Tijdens de training wordt de kans bepaald voor elk woord uit het lexicon, en voor rijtjes van twee of drie opeenvolgende woorden. Woorden worden weer gemodelleerd als een rij van klanken - fonemen genoemd." En op hun beurt worden die fonemen gemodelleerd als een - kort - rijtje van 'toestanden', zo legt Boves uit. "Meestal zijn er drie van dergelijke states: een voor het begin, een voor het midden en een voor het einde van de klank. Bij het trainen van de herkenner worden statistieken opgebouwd over het geluid dat hoort bij iedere state - als de klank uitgesproken wordt door heel veel verschillende sprekers, in heel veel verschillende woorden. Tijdens de herkenning wordt berekend wat, gegeven het waargenomen geluid en de kans op rijtjes van woorden, de meest waarschijnlijke rij woorden is."
Fundamenteel Een fundamenteel probleem van de Hidden Markov Models is dat aan het eind van de rit wel duidelijk is welk woord de meest waarschijnlijke uitkomst is, maar niet hoe waarschijnlijk. Boves: "Je kunt niet terugrekenen naar de absolute waarschijnlijkheid, want er zijn in dat proces zoveel arbitraire beslissingen genomen. Zonder een 'wereldbeeld' of zonder de beperkingen van een nauw omschreven protocol is correctie achteraf dan ook vrijwel onmogelijk. Hoe kan je anders ooit het verschil horen tussen wreck on nice beach en recognize speech? Het zal nog wel even duren voordat we onze videorecorder gesproken opdrachten kunnen geven en aan onze intelligent agent vragen om twee kaartjes voor een spannende film te reserveren in de buurt van een goed restaurant. Zulke kunstmatige intelligentie bestaat nog niet." De elektronische onzekerheid over wat iemand nu eigenlijk gezegd heeft en wat hij er mee bedoelt, is ook een fundamenteel probleem voor het ontwerpen van software voor de commerciële markt. Aasman: "Bij een grafische interface weet je zeker dat iemand dat ene knopje heeft ingedrukt. Bij spraak weet je dat dus nooit zeker. Vervolgens moet je weten dat bij shrink wrapped software - die je zo in een doos in een winkel kunt kopen - maar liefst 50 tot 70 procent van de kosten en moeite gaat zitten in het afvangen van de fouten die de gebruiker kan gaan maken met de bediening. Want een gewone computergebruiker doet nu eenmaal alles wat God verboden heeft met software. Bij een grafische interface weet je tenminste nog zeker dat de gebruiker dat ene knopje wèl heeft ingedrukt. Kun je nagaan voor welke problemen je met volledige spraakbesturing komt te staan." En Boves: "In een gewone menselijke dialoog dragen beide gesprekspartners bij aan correctie van vergissingen. In een spraak gestuurde mens-machinedialoog ligt de last van die correctie nog vrijwel volledig bij de mens."
Als het niet lukt: neerleggen!
Met dank aan het Amerikaanse leger
|
NRC Webpagina's 3 DECEMBER 1999
( a d v e r t e n t i e s )
|
| Bovenkant pagina |